代码预训练模型总结
这篇文章简单总结一些针对源代码的预训练模型,主要关注的是基于Transformer的大型预训练模型。此外,我们还主要关注针对各种下游任务的通用代码预训练模型,如果只是利用了预训练来提升模型在某一个下游任务上的表现,并没有在多个下游任务上进行验证,我们不认为这是一个通用的代码预训练模型,这里不会进行介绍。
CuBERT
Paper: https://proceedings.mlr.press/v119/kanade20a.html
Code: https://github.com/google-research/google-research/tree/master/cubert
预训练
CuBERT可以看做是BERT在代码文本上重新预训练后的模型。作者使用谷歌BigQuery收集了7.4M个Python文件,用来训练一个BERT模型。预训练任务与BERT一样,也是MLM和NSP。NSP中,CuBERT将两个Python表达式,看做是两个句子,也就是说每一行代码对应自然语言文本中的一句话。
评估
下游任务
CuBERT的所有下游任务数据都是基于ETH Py150经过处理得到的,它选择了6个下游任务:
- Variable-Misuse Classification。二分类任务,给定一个函数,判断这个函数中是否有变量误用的情况存在。
- Wrong Binary Operator。二分类任务,给定一个函数,判断这个函数中是否有任意一个二元运算符是错误的。
- Swapped Operand。二分类任务,给定一个函数,判断这个函数中是否有任何一个两边操作数不可交换的二元运算符,它的两个操作数被调换了位置。这里的两边操作数不可交换的二元运算符是指例如减号,除号等二元运算符,而加号等运算符的两边的操作数是可以交换的。
- Function-Docstring Mismatch。二分类任务,给定一个函数,以及一段自然语言写成的docstring,判断给定的函数和docstring是否是匹配的。
- Exception Type。多分类任务,作者从ETH Py150中的代码中,从
except {Exception}提取了前20个最常用的异常类型,然后把对应的位置挖空,使模型预测这里的异常类型是20个中的哪个。 - Variable-Misuse Localization and Repair。这是一个复杂的任务,包含两个指针任务,给定一个函数,这个任务首先需要指出变量误用的地方,然后第二个任务是指出函数中的另一个变量,是这个地方正确的变量。
Baselines
- Word2vec,用同样的预训练数据训练word2vec模型,然后用双向LSTM微调。
- Bi-LSTM,没有预训练,Variable-Misuse Localization and Repair任务上,用的是单向LSTM和指针网络。
- 没有预训练的Transformer。
结果
RQ1: 预训练上下文embedding是否有效?
预训练上下文embedding是对应于非上下文的embedding预训练,即word2vec预训练。为了验证预训练上下文embedding是否有效,CuBERT在5个分类任务上进行了实验。
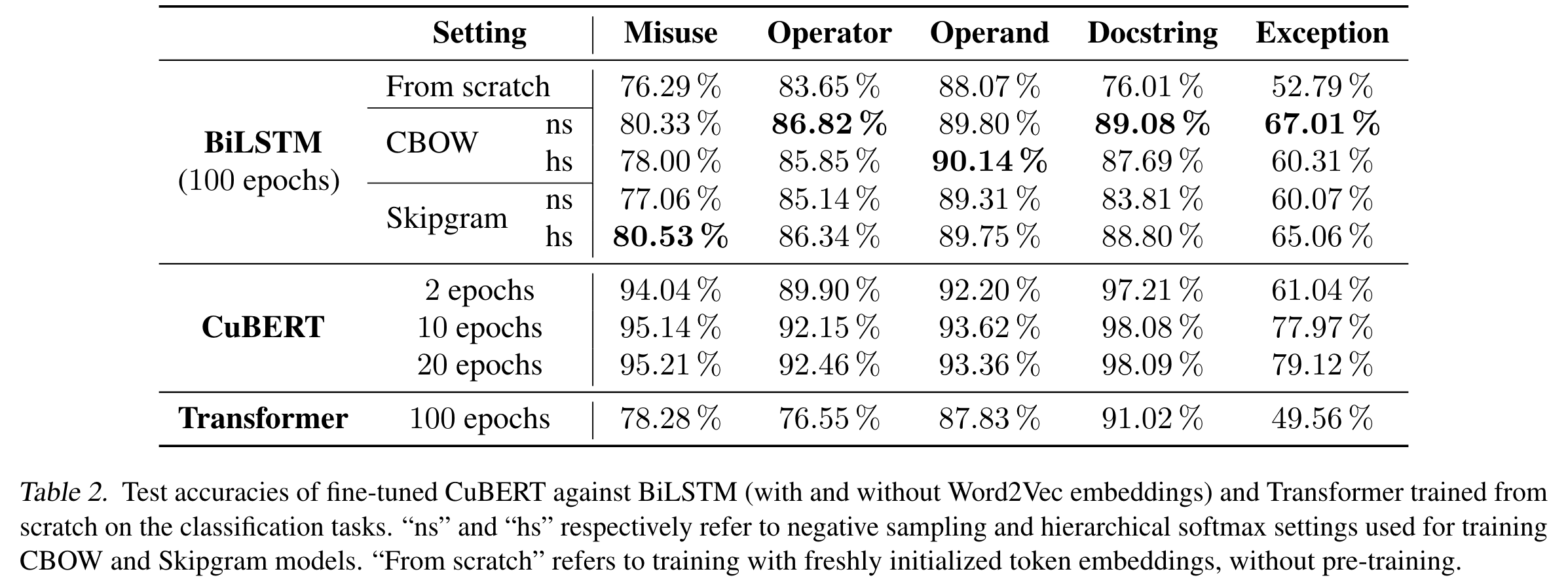
可以看到,微调20轮的CuBERT比100轮的BiLSTM任何时候都有绝对的优势,说明预训练上下文embedding在效果和效率上都十分有效。
RQ2: 是预训练起了效果,还是Transformer的帮助?
还是看上图,最后一行是用没有预训练的Transformer的实验结果,因此可以看出,预训练也是起了至关重要的作用。
RQ3: 当我们将微调的训练集缩小,会发生什么?
作者将微调时的数据集大小分别设置为原来的33%,66%和100%进行实验,结果如下。
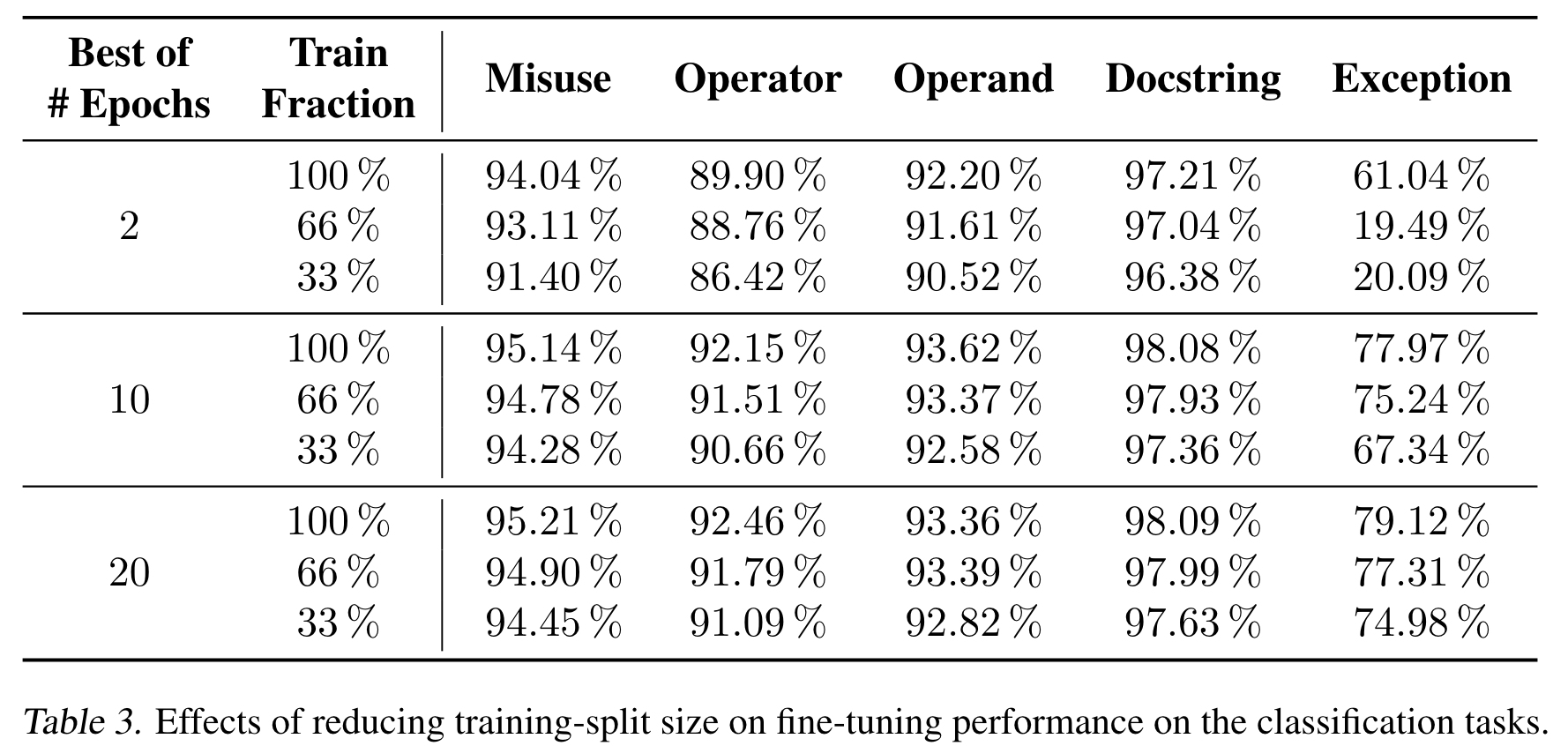
可以看到,Function-Docstring Misuse任务对微调数据的减少最不敏感,也就是对数据量的鲁棒性最强。而Exception Type则对微调数据的规模十分依赖。而对比上面两个表格,可以发现,在某些任务上,CuBERT即使只用33%的数据微调2轮,也比一些baselines的效果好。
RQ4: 最大输入长度的影响。
这个RQ探究最大输入长度对CuBERT在下游任务上的表现的影响。
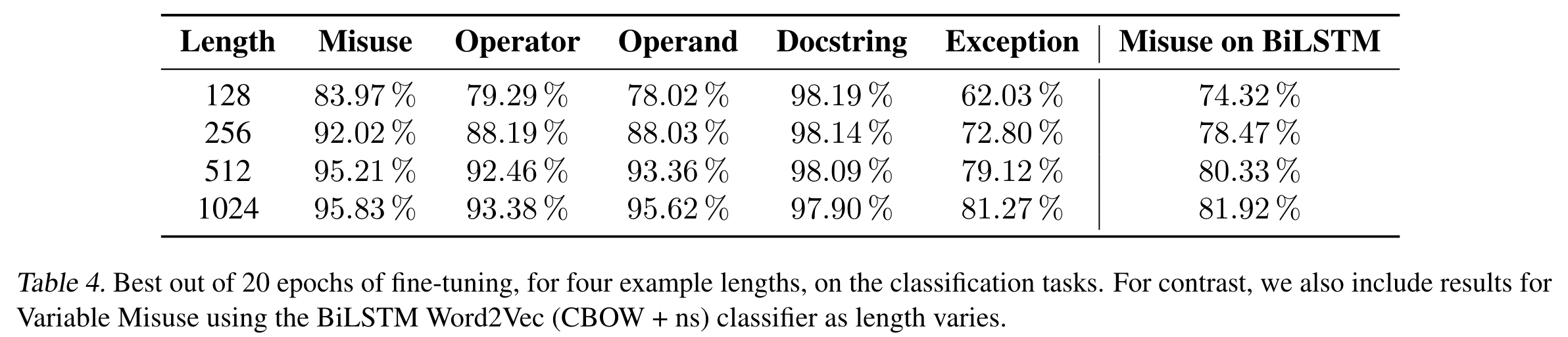
首先还是Function-Docstring Misuse任务,它仍然对输入长度的减少不敏感。作者认为模型在这个任务上主要关注的是Docstring和函数签名,而对函数体中的内容则关注不多。
RQ5: 在复杂任务上的表现。
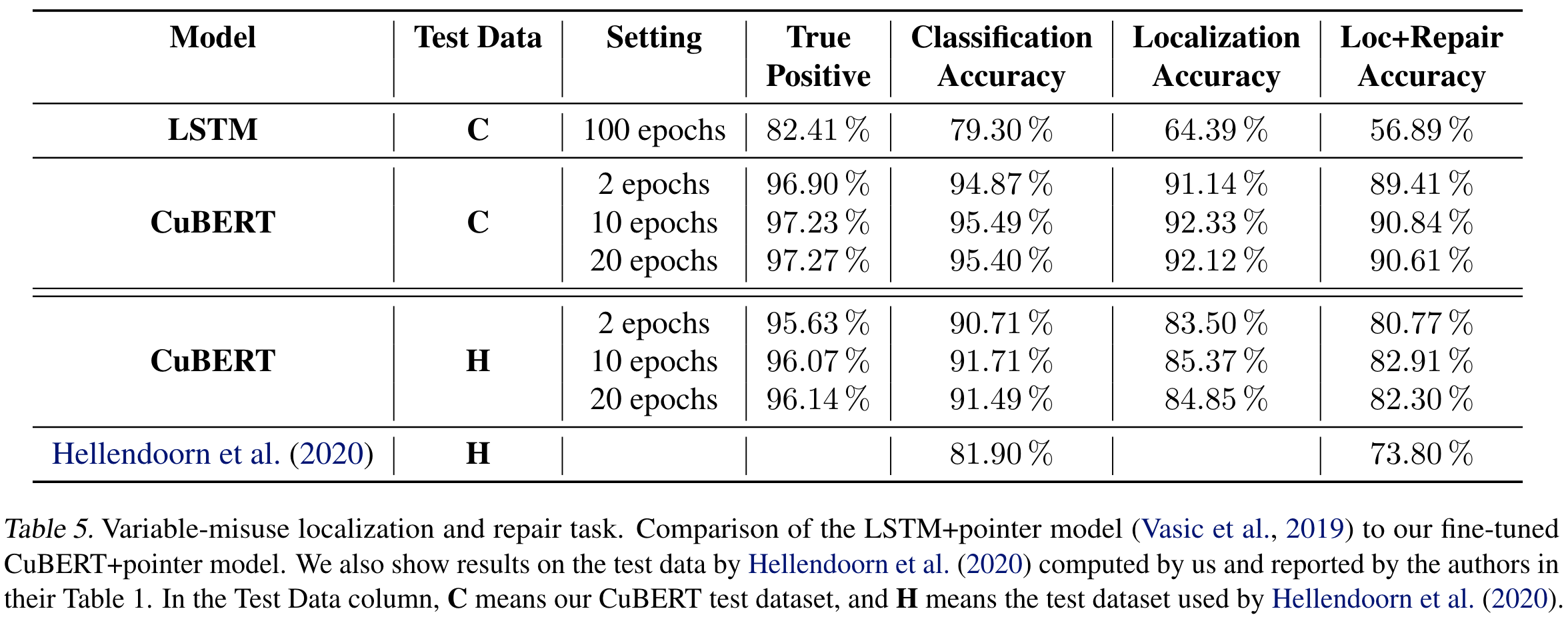
可以看到,效果还是很好的,其中Hellendoorn et al.的方法是用GNN,Transformer和RNN的一个模型,它使用了代码的AST,DFG和CFG,然而还是没有CuBERT效果好。
结论
CuBERT是第一个尝试用预训练代码上下文embedding来训练BERT的模型,比之前的非上下文,非预训练的方法取得了巨大的提升。此外,作者在最后也说到可以将代码的结构信息加入进来,还提出了对模型的大小进行减小,以在准确率和模型效率上达到一个平衡。
CodeBERT
Paper: https://aclanthology.org/2020.findings-emnlp.139/
Code: https://github.com/microsoft/CodeBERT
CodeSearchNet
介绍CodeBERT之前,首先介绍一下CodeSearchNet(CSN),在CodeBERT之后,CSN成为了代码预训练模型领域比较常用的数据集,不管是预训练的数据集还是下游任务的数据集。
CSN是从GitHub上爬取的数据,包含6个语言,Java,Python,JavaScript,Go,PHP和Ruby。