LLVM IR (Intermediate Representation),是LLVM所使用的代码表示。我们都知道LLVM把整个编译过程分为三个部分,前端(frontend),编译优化,后端(frontend)。这是LLVM针对不同的源代码和不同的目标架构所使用的低耦合解决办法,前端负责将不同的编程语言写成的代码转换为统一的表示,然后编译优化部分进行优化,最后针对不同的平台,再使用不同的后端生成对应的机器码。这样,编译优化部分就不需要随着编程语言和目标平台进行调整。而前端所生成的统一表示,就是LLVM IR。IR是源代码的完整表示,所以我们只需要IR就可以替代源代码,不需要其他的任何信息。
这篇文章我会简单介绍一下IR,主要参考的是在2019 EuroLLVM Developers’ Meeting 上,V. Bridgers和F. Piovezan带来的教程”LLVM IR Tutorial - Phis, GEPs …”。
什么是IR IR是一种低级编程语言,它有着像RISC的指令集。同时,它与例如汇编之类的语言不同的是,IR可以表达高层次的想法,也就是说,高级编程语言可以非常清楚,确定地映射到IR上。同时,他的设计还有利于编译器进行优化。
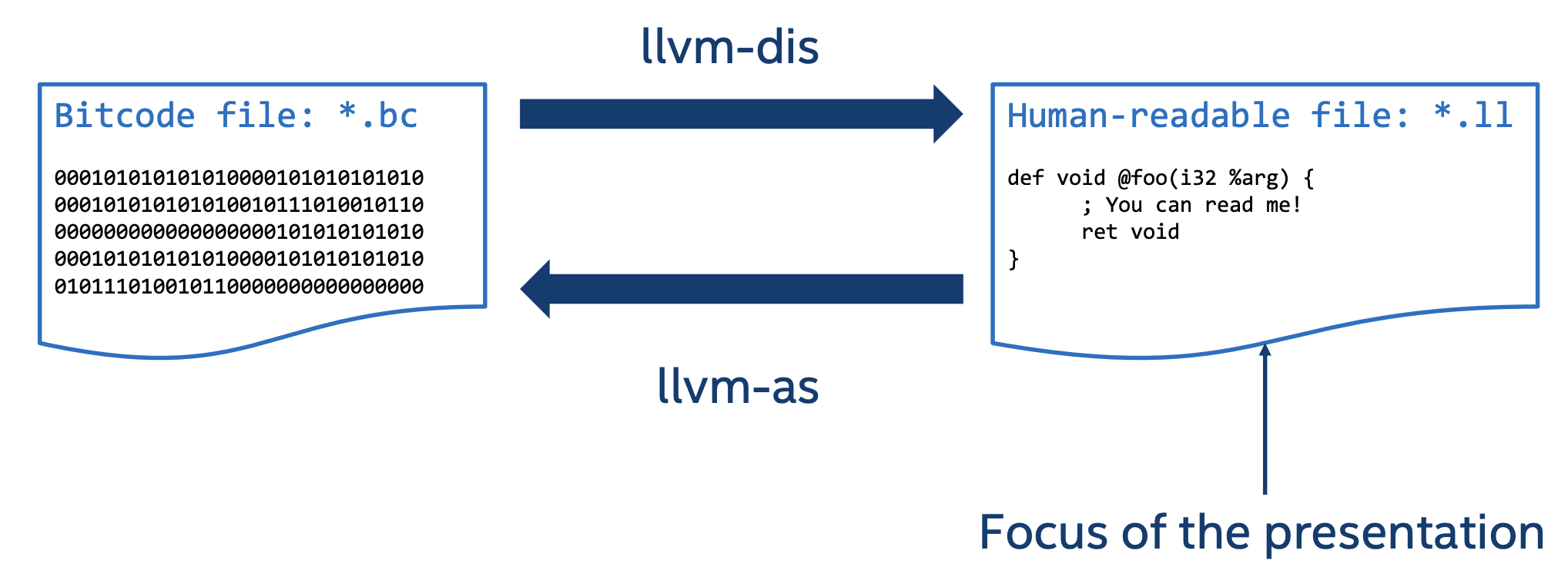
IR的表现形式 IR的表示形式有三种,一种是基于二进制的位码(bitcode),文件后缀为bc。第二种是有利于人们阅读的形式,文件后缀是ll。第三种是LLVM在编译和优化IR时的,在内存时的中间形式,这个设计是LLVM之所以编译快的一个重要原因,它的每一步不需要生成中间文件,而是直接在内存中生成中间形式。
也就是说,我们可以看到的IR的形式就是两种,文件后缀为bc和ll的表示。我们可以通过命令得到这两种格式的文件。
1 2 clang -c -emit-llvm main.c
针对C++只需将clang替换为clang++即可。通过查阅clang命令的文档,我们可以发现,这几个选项的含义。
1 2 3 -c Only run preprocess, compile, and assemble stepsfor assembler and object files
这两种形式可以相互转化。从bc文件转换为ll文件的过程称为llvm-dis,相反则为llvm-as,命令很简单:
1 2 llvm-dis main.bc
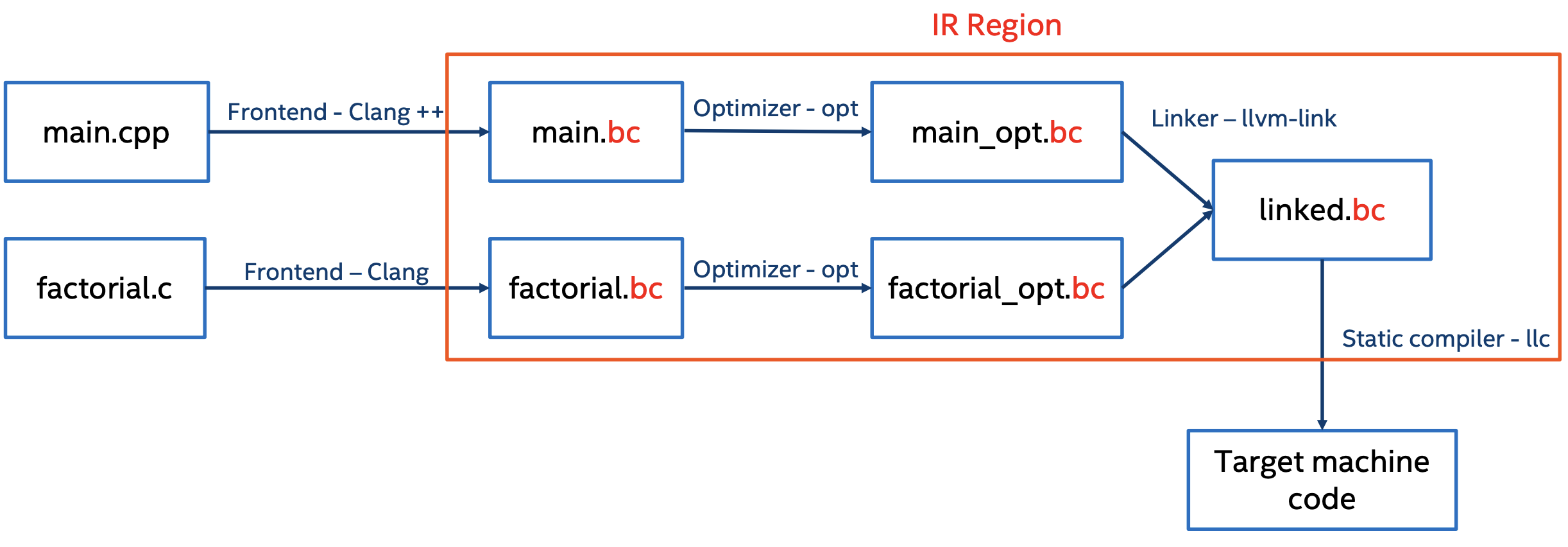
IR在LLVM编译过程中的位置 IR可以使不同语言写成的代码在LLVM的编译过程中均转换成IR的表示形式,从而可以进行链接。
从上图可以看到,我们写了一个main.c文件,然后其中会调用一个计算阶乘的函数,而这个函数是用c++写成的,在factorial.cpp文件中。现在我们就可以先用clang编译main.c,然后再用clang++编译factorial.cpp,优化后,我们可以把这两个本来用不同语言写成的程序进行链接。最后再针对目标平台生成机器代码。
在整个过程中,我们可以看到,IR在整个编译,优化,链接的过程中都存在,也就是说,IR是LLVM在除了前端和后端的过程中,完全表示代码的工具。
IR文件的组成 我们重点研究ll文件,首先,ll文件中,每一行在分号(;)之后表示注释。
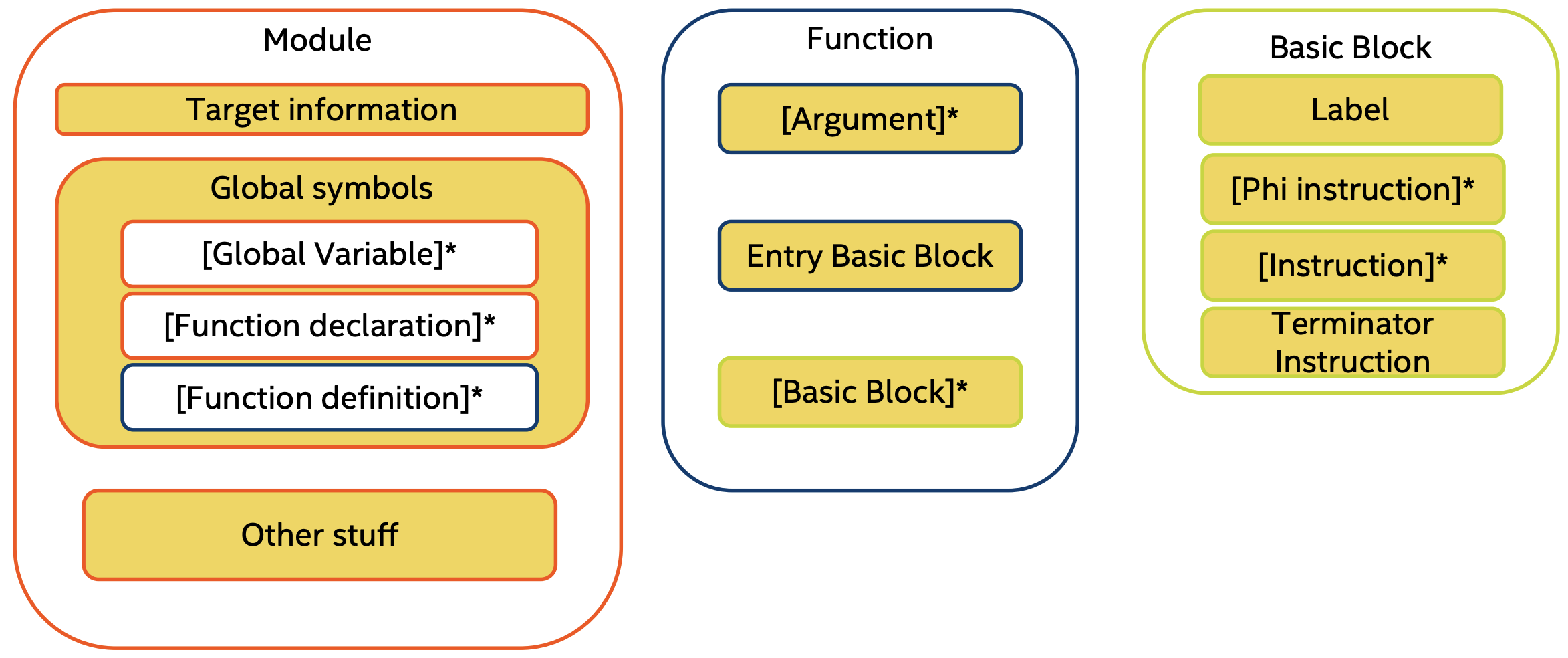
首先,一个module就是一个模块,可以是从一个源文件中编译而来,也可以是链接而来等等。一个模块有以下几部分
Target information,就是目标平台相关的信息
Global symbols,全局符号,可能包括(*号是指0个或多个)
Global variable,全局变量
Function declaration,函数声明
Function definition,函数定义
其它
下面是一个ll文件的开头,该ll文件来自于C语言写成的hello world文件。
1 2 3 4 = "hello.c" target datalayout = "e-m:o-i64:64-i128:128-n32:64-S128" target triple = "arm64-apple-macosx13.0.0"
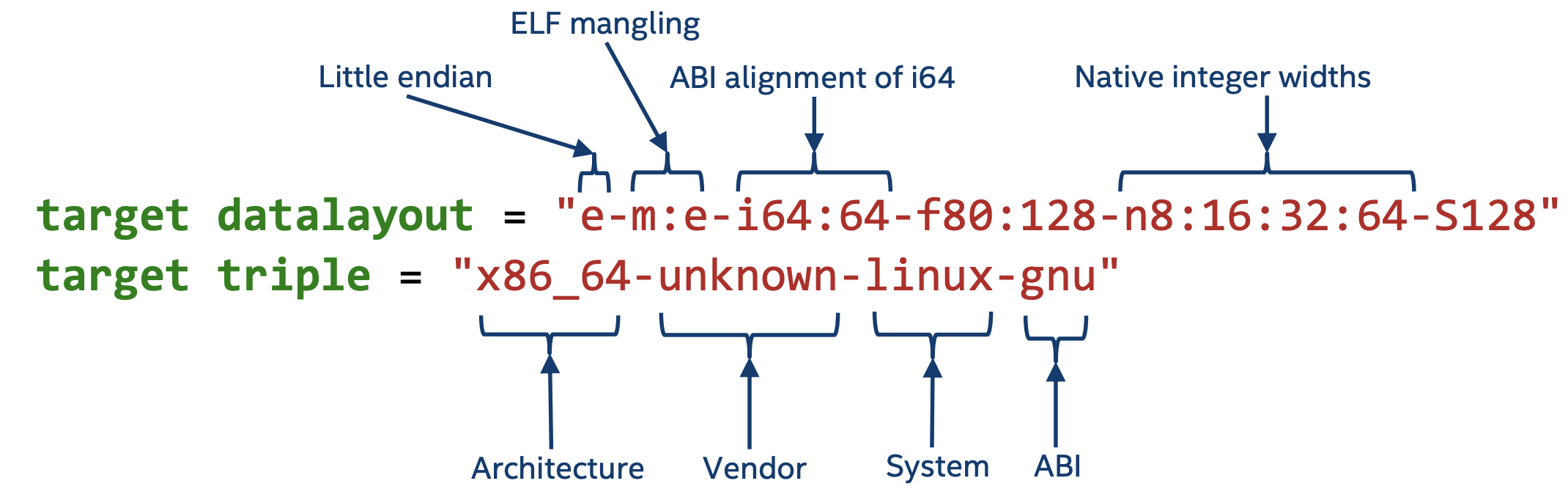
第一行是注释,表示当前module的ID是hello.c,这也是源文件的名字,这从第二行也可以看出来,而如果该module是由链接得来的,这里的source_filename字段则为llvm-link。
第三第四行主要是一些编译时的目标机器的一些信息,主要的字段解释如下。
Global symbols 这里记录一些全局的符号。hello.ll文件中,这一部分的内容如下。
1 2 3 4 5 6 7 8 9 10 11 @.str = private unnamed_addr constant [13 x i8 ] c "hello world!\00 " , align 1 define i32 @main () #0 {%1 = alloca i32 , align 4 store i32 0 , i32 * %1 , align 4 %2 = call i32 (i8 *, ...) @printf (i8 * getelementptr inbounds ([13 x i8 ], [13 x i8 ]* @.str , i64 0 , i64 0 ))ret i32 0 declare i32 @printf (i8 *, ...) #1
为了更好的说明,我们在这里再举一个简单的代码main.c
1 2 3 4 5 6 int factorial (int val) ;int main () return factorial(2 ) * 7 == 42 ;
这段代码很简单,我们首先声明了一个计算阶乘的函数,然后在main函数里计算了2的阶乘,乘7之后,判断是否等于42,并将结果返回。main.c编译成的main.ll在全局符号部分如下。
1 2 3 4 5 6 7 8 9 10 11 12 define i32 @main () #0 {%1 = alloca i32 , align 4 store i32 0 , i32 * %1 , align 4 %2 = call i32 @factorial (i32 2 )%3 = mul nsw i32 %2 , 7 %4 = icmp eq i32 %3 , 42 %5 = zext i1 %4 to i32 ret i32 %5 declare i32 @factorial (i32 ) #1
Global variable 首先,所有的literal的字符串都被记录为全局变量,例如我们的hello world程序中,”hello world!”字符串就出现在了全局变量中:
1 @.str = private unnamed_addr constant [13 x i8 ] c "hello world!\00 " , align 1
而在main.ll文件中,并没有全局变量。
Function declaration 这里表示函数的声明,比如我们如果在main.c中想使用外部的阶乘函数,那么我们需要在main函数之前声明这个阶乘函数的签名。而这一部分在ll文件中被放在了main函数下面:declare i32 @factorial(i32) #1。这个很好理解,和高级语言很相似。最后的#1是函数的attribute group,这个在后面Other stuff中会介绍。
Function definition 这里是函数的定义,包含函数的签名和函数体,是IR最主要的部分。比如main.ll中的函数定义为。
1 2 3 4 5 6 7 8 9 10 define i32 @main () #0 {%1 = alloca i32 , align 4 store i32 0 , i32 * %1 , align 4 %2 = call i32 @factorial (i32 2 )%3 = mul nsw i32 %2 , 7 %4 = icmp eq i32 %3 , 42 %5 = zext i1 %4 to i32 ret i32 %5
首先是函数的签名,i32表示返回值类型为32位整数,@main为函数名,后面没有参数,#0是attribute group,然后就是方法体。
方法体的前两行我看着并没有什么用,在源代码中也没有对应的语句,不知道为什么会有这两句。首先是alloca命令,将一个i32类型的内存空间分配给%1,%1是一个指针,指向的是一个地址空间。然后使用store命令将一个i32值0储存到%1指向的i32内存空间中。
这里%1是一个变量,IR中的变量有两种,第一种是局部变量,以百分号%开头,局部变量有命名(named)和未命名(unnamed)两种,未命名的局部变量用百分号后面跟递增的数字表示;另一种是全局标识符,用@开头,全局标识符包括函数名和全局变量。标识符匹配的正则表达式可以写成[%@][-a-zA-Z$._][-a-zA-Z$._0-9]*。
然后是第三行到最后,首先在第三行,call命令是调用函数的指令,它调用factorial函数,参数是i32类型的值2,然后将i32类型的返回值赋值给%2。下面一行,mul将i32值%2和7相乘,结果赋值给%3。然后icmp是指整数比较指令,eq比较i32值%3和42是否相等,然后将结果赋值给%4。最后,由于%4是一个布尔类型(在IR中为1位整数),而我们的返回值类型为i32,因此,我们要将结果转换类型,将i1类型的%4,转换为i32类型,并赋值给%5,最后将%5返回。
可以看到,IR是一个非常强的强类型语言,每一步都明确指定了期望的类型,这样有利于后期进行编译优化。
Other stuff main.ll的other stuff如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 attributes #0 = { noinline nounwind optnone ssp uwtable "frame-pointer" = "non-leaf" "min-legal-vector-width" = "0" "no-trapping-math" = "true" "probe-stack" = "__chkstk_darwin" "stack-protector-buffer-size" = "8" "target-cpu" = "apple-m1" "target-features" = "+aes,+crc,+crypto,+dotprod,+fp-armv8,+fp16fml,+fullfp16,+lse,+neon,+ras,+rcpc,+rdm,+sha2,+sha3,+sm4,+v8.5a,+zcm,+zcz" }attributes #1 = { "frame-pointer" = "non-leaf" "no-trapping-math" = "true" "probe-stack" = "__chkstk_darwin" "stack-protector-buffer-size" = "8" "target-cpu" = "apple-m1" "target-features" = "+aes,+crc,+crypto,+dotprod,+fp-armv8,+fp16fml,+fullfp16,+lse,+neon,+ras,+rcpc,+rdm,+sha2,+sha3,+sm4,+v8.5a,+zcm,+zcz" }!llvm.module.flags = !{!0 , !1 , !2 , !3 , !4 , !5 , !6 , !7 , !8 }!llvm.ident = !{!9 }!0 = !{i32 2 , !"SDK Version" , [2 x i32 ] [i32 13 , i32 1 ]}!1 = !{i32 1 , !"wchar_size" , i32 4 }!2 = !{i32 1 , !"branch-target-enforcement" , i32 0 }!3 = !{i32 1 , !"sign-return-address" , i32 0 }!4 = !{i32 1 , !"sign-return-address-all" , i32 0 }!5 = !{i32 1 , !"sign-return-address-with-bkey" , i32 0 }!6 = !{i32 7 , !"PIC Level" , i32 2 }!7 = !{i32 7 , !"uwtable" , i32 1 }!8 = !{i32 7 , !"frame-pointer" , i32 1 }!9 = !{!"Apple clang version 14.0.0 (clang-1400.0.29.202)" }
可以看到,都是一些相关的信息,这对于我们分析,优化IR的作用不大。其中需要注意的是我们之前提到的attributes group,即attributes #0和attributes #1。从上面可以看到@main函数的attributes group是#0,@factorial(i32)的attributes group是#1。这里面是关于函数的一些属性,由于多个函数可能会拥有同样的属性,这些属性就被储存在了这里,上面的函数只需要引用ID就可以了。
Basic Blocks 接下来我们通过一个例子进行讲解,就是使用递归方法实现的阶乘函数。
1 2 3 4 5 6 int factorial (int val) if (val == 0 )return 1 ;return val * factorial(val - 1 );
对应的IR如下,注意这里为了方便阅读,将一些标识符改成了具有实际意义的单词。
1 2 3 4 5 6 7 8 9 10 11 define i32 @factorial (i32 %val ) {%is_base_case = icmp eq i32 %val , 0 br i1 %is_base_case , label %base_case , label %recursive_case ret i32 1 %1 = add i32 -1 , %val %2 = call i32 @factorial (i32 %0 )%3 = mul i32 %val , %1 ret i32 %2
然后我们可以从IR中看到,IR被分成了三部分,第一部分是前两行,然后是base_case下边的一行,最后是recursive_case之后的几行。这三部分的每一部分其实是一个Basic Block(BB)。每一个BB是由以终止指令(terminator instruction)结尾的一系列指令组成的,除了最后一个指令是终止指令以外,其它指令均不是终止指令。
终止指令有以下几种类型:
Branch - br,表示跳转到指定BB。
Return - ret,表示返回。
Switch - switch,与高级语言中的switch一样。
Unreachable - unreachable,程序不会访问的标识,后面会介绍。
处理异常相关的指令。
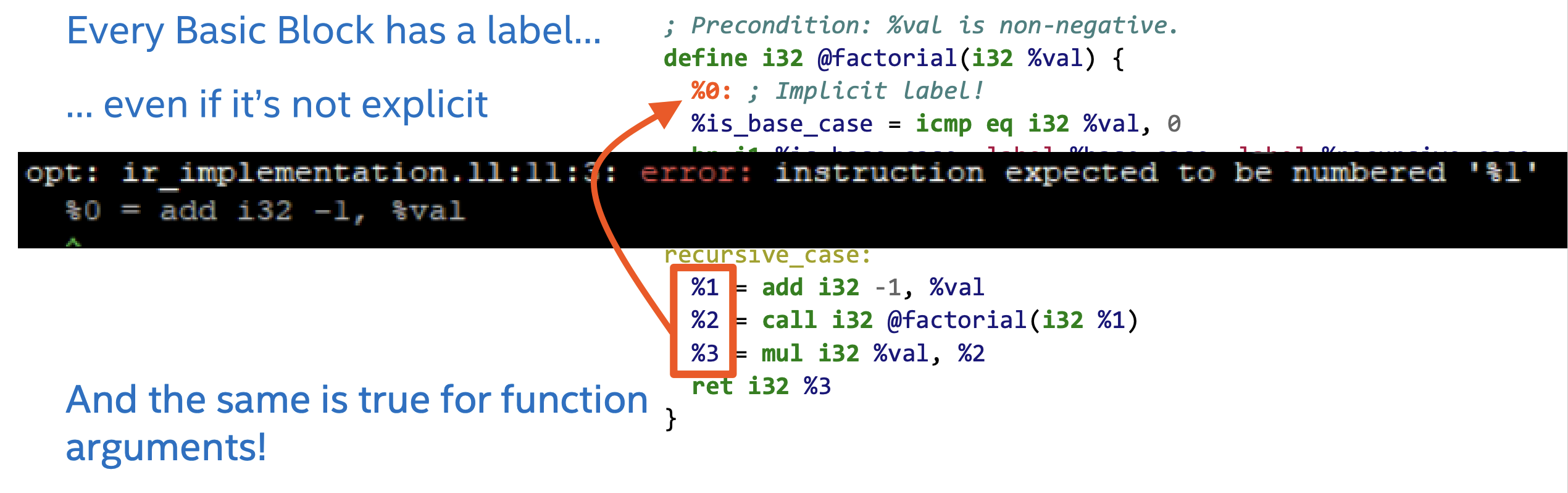
一个BB内的指令是不存在任何执行分支的,也就是说,一个BB内的指令一定是顺序执行的。每一个BB都有一个label,比如例子中的base_case和recursive_case。但是我们发现,第一个BB似乎没有label,那是因为它的label是隐式的。
当IR中没有显式地给出第一个BB的label时,相应的label就是%0。这时,如果我们将第一个局部变量的名字改为%0,如下图所示。
那么我们使用opt -verify命令验证修改过后的IR文件是否正确时,会出现如下的错误。
可以看到,错误信息是%0被占用了,这就说明第一个BB的隐式label为%0。对于函数参数来说同理,如果我们没有显式地给出参数名称,那么默认也是%0。
再给出一个例子,这个例子是我在自己的电脑上生成的factorial.ll文件的函数定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 define i32 @factorial (i32 %0 ) #0 {%2 = alloca i32 , align 4 %3 = alloca i32 , align 4 store i32 %0 , i32 * %3 , align 4 %4 = load i32 , i32 * %3 , align 4 %5 = icmp eq i32 %4 , 0 br i1 %5 , label %6 , label %7 6 : store i32 1 , i32 * %2 , align 4 br label %13 7 : %8 = load i32 , i32 * %3 , align 4 %9 = load i32 , i32 * %3 , align 4 %10 = sub nsw i32 %9 , 1 %11 = call i32 @factorial (i32 %10 )%12 = mul nsw i32 %8 , %11 store i32 %12 , i32 * %2 , align 4 br label %13 13 : %14 = load i32 , i32 * %2 , align 4 ret i32 %14 %0 ,那么第一个BB的label就是%1 ,而函数体中第一个变量就是%2 。"CFG for 'factorial' function" {= "CFG for 'factorial' function" 0x600000b71fc0 [shape= record, color= "#3d50c3ff" , style= filled, fillcolor= "#b9d0f970" , label= "{%1}" ]0x600000b71fc0 -> Node0x600000b72000 0x600000b72000 [shape= record, color= "#b70d28ff" , style= filled, fillcolor= "#b70d2870" , label= "{%2|{<s0>T|<s1>F}}" ]0x600000b72000 :s0 -> Node0x600000b72180 0x600000b72000 :s1 -> Node0x600000b72080 0x600000b72080 [shape= record, color= "#b70d28ff" , style= filled, fillcolor= "#bb1b2c70" , label= "{%6}" ]0x600000b72080 -> Node0x600000b72000 0x600000b72180 [shape= record, color= "#3d50c3ff" , style= filled, fillcolor= "#b9d0f970" , label= "{%9}" ]
这个文件还是可以看懂的。每一行定义了一个节点或者边。